Maschinelle Identifikation der Wortwiederholbarkeit in Textinhalten von Deutsch-Lernplattform DAZonline mit Vorschlaggenerierung zur Füllung der Lücken.
DAZonline, Natural Language Processing (NLP), Graphen, PHP, TypeScript, Python, Docker
Die Web-2.0-Webseite https://dazonline.ch enthält eine Galerie von Sprach-Lernbildern. Ein Lernbild besteht aus einem Titel, einem Bild und einem oder mehreren darauf positionierten Lernpunkten. Jeder Lernpunkt beschreibt das darunterliegende visuelle Element schriftlich, einmal kurz alleinstehend und einmal als Satz im Kontext des gesamten Bildes. Die schriftliche Beschreibung kann mithilfe eines digitalen Sprachwerkzeugs durch Anklicken eines Lautsprecher-Icons auditiv wiedergegeben werden.
Ein Beispiel für ein Lernbild ist eine Fotografie einer Katze mit einer toten Maus im Mund, bezeichnet mit «Jagd». Auf der Katze befindet sich eine Markierung mit der Beschreibung «eine Katze» und dem Kontext «Die Katze hat eine Maus erbeutet».
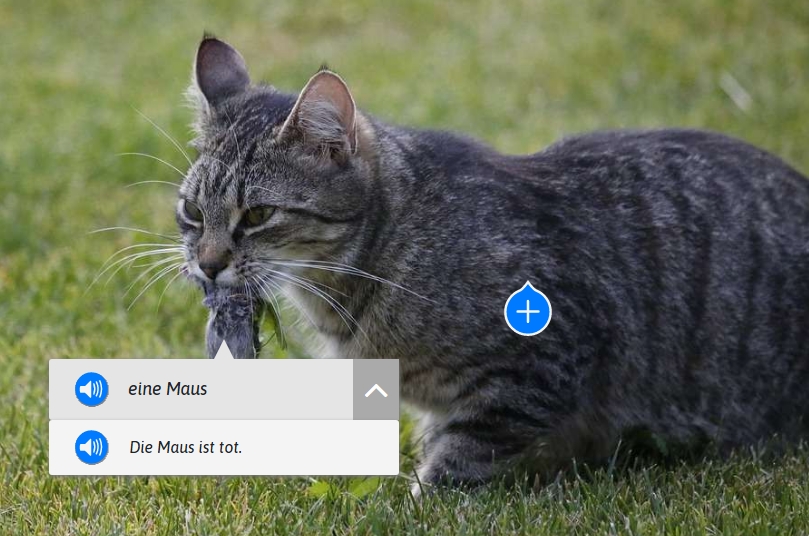
DAZonline - Lernbild «Jagd»
Bildquelle: https://pixabay.com/images/id-4454406
Mittels dieser Lernbilder sollen Personen, bisher hauptsächlich Kinder, deutsche Wörter und Redewendungen als Fremdsprache auf assoziative, natürliche Weise erlernen. Das funktioniert, indem das (sprach)lernende Kind die dargestellte Situation aus dem Weltwissen heraus versteht. Wiederholungen von sprachlichen Formen (Wörter und Phrasen) in mehreren unterschiedlichen Lernbildern ermöglichen das situationsübergreifende Lernen. Editoren, beispielsweise Kindergartenlehrpersonen, legen Lernbilder primär in Eigenregie nach den aktuellen Bedürfnissen der Sprachlernenden an.
Editoren sollen Informationen über die wichtige Metrik der Wortwiederholbarkeit zur Verfügung haben. Deshalb sollen die Wortüberlappungen zwischen den einzelnen Lerneinheiten maschinell identifiziert werden, so dass Editoren Bereiche mit fehlenden Überlappungen identifizieren können.
Des Weiteren sollen maschinell Vorschläge für spezifische textliche Inhalte von neuen Lernbildern generiert werden.
Diese Vorschläge sollen so gestaltet sein, dass sie Lernpunkte mit fehlenden Wortüberlappungen und selten vorkommende Wörter ergänzen.
Fragestellungen:
Das Ausarbeiten und Integrieren einer Methode zur algorithmischen Identifikation der vorhandenen Wortüberlappungen, im Kontext einer lernförderlichen Wiederholbarkeit auf der Lernplattform für Deutsch DAZonline, ist gelungen. Die Editoren der Inhalte haben nun Informationen über diese wichtige Metrik der Lernförderlichkeit zur Verfügung und können Lerneinheiten mit zu niedriger Wortüberlappung identifizieren. Mit Hilfe der maschinell generierten Textvorschläge für neue Lerneinheiten können sie diese Lücken im Angebot gezielt schliessen. Zudem wurden die neuen Informationen genutzt, um Lernenden Vorschläge für ein nächstes Lernbild anzuzeigen, welche mindestens ein bekanntes Wort enthalten. Ob ein positiver Effekt auf den Lerngewinn entsteht, beziehungsweise wie gross dieser ist, kann in einer Folgearbeit erforscht werden.
Wortüberlappung von Lernpunkten werden aufgrund von gemeinsamen Wörtern (gleiche Grundform und gleiche Wortart) identifiziert. Die dafür nötige Verarbeitung der Sprache findet mit der Library ParZu (GNU GPL v2 Lizenz) statt. Die Vorschläge für neue Textinhalte werden auf der Basis des Textes der Lerneinheiten generiert, die eine unzureichende Anzahl von Wortüberlappungen aufweisen. Die Textvorschläge bestehen zum einen aus einzelnen Wörtern (den vorhandenen Nomen und Verben) und zum anderen aus Teilsätzen. Die Informationen zu den bestehenden Wortüberlappungen und die Vorschläge für neue Inhalte werden direkt auf der bestehenden Webseite angezeigt
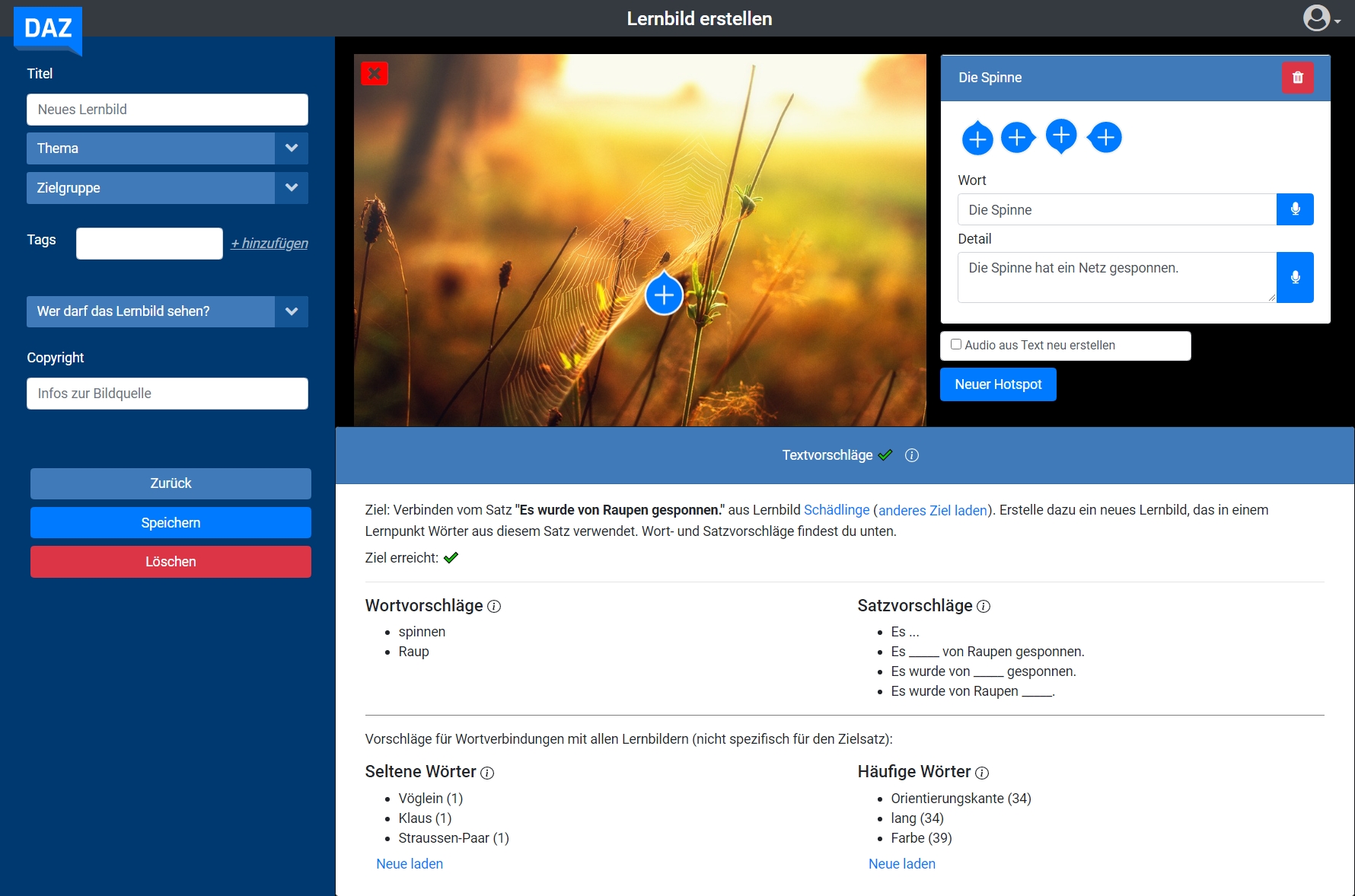
DAZonline - Neues Lernbild erstellen mit Textvorschlägen
Bildquelle: https://pixabay.com/images/id-4166897
Die Genauigkeit der Sprachverarbeitung ist mit 97% ausreichend, kann aber verbessert werden, etwa durch den Einsatz eines leistungsfähigeren Tools wie spaCy. Die Identifikation der bestehenden Wortüberlappungen hat eine Präzision von 94% erzielt, ebenfalls ein zufriedenstellendes Ergebnis. Daten zur linguistischen Struktur der Textinhalte (Abhängigkeitsanalyse) werden maschinell generiert aber weder für die Auswertung der Wortüberlappungen noch zur Vorschlaggenerierung verwendet. Das Einbeziehen dieser zusätzlichen Dimension bietet Potential zur Verbesserung der Zielerreichung.
Bachelor Thesis
Projektdauer: September 2020 bis März 2021
Aufwand: 360 Personenstunden
Teamgrösse: 1
Susanne Grassmann, info@dazonline.ch
Verein Lernbild
Dimitri Vranken, dimitri.vranken@students.fhnw.ch
Samuel Fricker, samuel.fricker@fhnw.ch
Marcel Gygli, marcel.gygli@fhnw.ch
Mia Braundwalder, mia.braunwalder@fhnw.ch