Steigende Kundenanforderungen führen zu immer einzigartigeren Produkten, die exakt auf die Kundenbedürfnisse zugeschnitten sind. Bei der Gestaltung effizienter und wettbewerbsfähiger Geschäftsprozesse ist eine kontinuierlich hohe Datenqualität der Schlüssel für die Umwandlung von Kunden-und Prozessdaten in Wissen und Kunden-Mehrwert

Unternehmen entwerfen für jeden Auftrag eine auf den Kunden zugeschnittene Lösung und wenden dabei für die Fertigung zum Teil gleiche, zum Teil aber komplett neue Verfahrensschritte an. Es entstehen immer wieder neue Kundenbedürfnisse und Technologiefortschritte eröffnen neue Möglichkeiten.
In diesem dynamischen und herausfordernden Umfeld sind vier Schweizer KMU tätig, welche eines gemeinsam haben: sie betreiben einen hohen Aufwand für die Erstellung von Angeboten und der Anteil an Aufträgen, der aus diesen Angeboten resultiert, liegt meist unter einem Drittel. Ein Projektteam am Institut für Business Engineering IBE hat es sich deshalb zum Ziel gesetzt, mit Hilfe von Data Science die Herausforderungen der Unternehmen in diesem dynamischen Umfeld anzugehen und nach Mustern in den Vergangenheitsdaten zu suchen.
Beim ersten Unternehmen wurde die Data Science-Methode Process Mining angewendet. Die Process Mining-Analyse lieferte die Basis für konkrete Produktionsverbesserungen. Die Umstellung auf roboterunterstützte Produktionsinseln kombiniert mit einer Durchlaufzeit-Optimierung über den gesamten Auftragsabwicklungsprozess inklusive Planung erzielte folgende Resultate: eine Reduktion der Herstellkosten pro Stück von CHF 8.69 auf CHF 3.96 (-54%), eine Reduktion der Durchlaufzeit von 10.5 Tage auf 4.5 Tage (-60%) sowie dadurch gesamthaft eine Umsatzsteigerung pro Mitarbeitenden von kCHF 350 auf kCHF 660 (+90%).
Bei zwei weiteren Unternehmen wurden Angebotsdaten aus der Vergangenheit genauer analysiert. Jedes Angebot hat eine eigene Nummer in der Datenbank und beinhaltet diverse Informationen über den Kunden, über das angefragte Produkt, über den offerierten Preis inklusive Rabattinformationen und die Angabe, ob am Ende aus diesem Angebot ein Auftrag resultiert oder nicht. Mit diesen Informationen konnte das Projektteam ein Klassifikationsverfahren mit zwei Klassen durchführen: Klasse 1 sind Angebote, die zu einem Auftrag führten. Klasse 0 sind die nicht erfolgreichen Angebote. Die Frage lautete also, welche Angebotseigenschaften haben einen Einfluss auf die Zu- oder Absage bei einem Angebot? Das beste Ergebnis lieferten Decision Trees, welche in den Testdaten über 80% der Angebote richtig klassifizieren konnten. Weiter zeigte diese Data Science-Methode zusätzliche Informationen über die wichtigsten Einflussfaktoren. Beispielsweise wurde erkannt, welche Rabattklassen am effektivsten sind und wie diese die Wahrscheinlichkeit einer Zusage beeinflussen.
Beim vierten Unternehmen hat das Projektteam ein Regressionsmodell entwickelt, welches durch die Angabe von wichtigen Produkteigenschaften den Produktpreis berechnet. Dort gelang es, Angebote mit einer Kostenspanne von bis zu CHF 4'000.- mit einer Genauigkeit von +/- CHF 400.- vorherzusagen.
Die Ergebnisse sind das Resultat eines langen und zum Teil schwierigen Prozesses. Die Daten aus den ERP-Systemen der vier Unternehmen mussten zunächst in einem aufwendigen und iterativen Prozess bereinigt werden. Erst dann war es möglich, diverse Modelle zu prüfen. Die ersten Ergebnisse wiederum zeigten erneut Schwachstellen in den Daten auf. So waren mehrere Iterationen notwendig, um am Ende belastbare Resultate zu erzielen.
Das Vorgehensmodell CRoss-Industry Standard Process for Data Mining (CRISP-DM) widerspiegelt diesen iterativen Prozess und ist auch deshalb das führende Modell für Data Science- Projekte (vgl. Abb. 1).
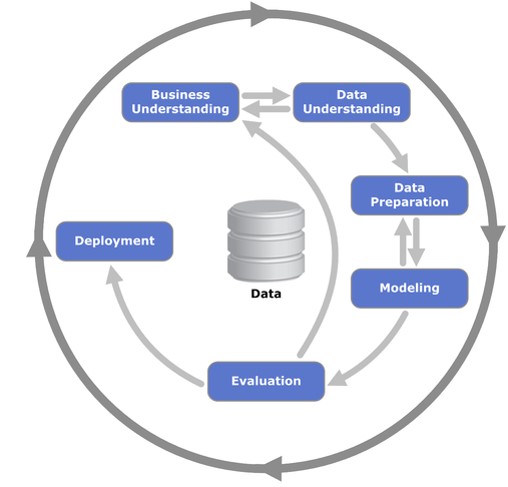
Abb. 1: CRoss-Industry Standard Process for Data Mining (CRISP-DM)
Die Erfahrung zeigt, dass Datenanalyse und Datenaufbereitung sehr ressourcenintensive Schritte sind (vgl. Abb. 2). Bei allen vier Unternehmen wurden die erkannten Mängel in der Datenqualität jedoch zum Anlass genommen, um Verbesserungsmassnahmen einzuleiten. Dadurch konnte die Datenqualität verbessert und der künftige Bereinigungsaufwand für Data Science-Projekte reduziert werden.
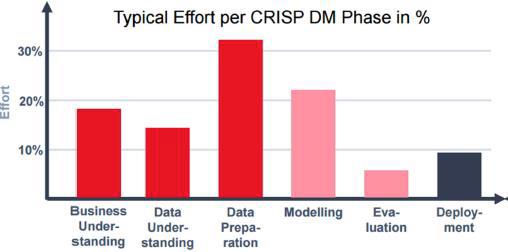
Abb. 2: Typischer Aufwand pro CRISP-DM Phase, Thomas Zeutschler, IT Applications in Business Analytics, Hochschule Düsseldorf
Das CRISP-DM Modell trägt diesem zusätzlichen Nutzen in Data Science-Projekten zu wenig Rechnung und die Schritte Datenanalyse und Datenaufbereitung werden als lästige, nicht wertschöpfende Arbeit angesehen. Dieser Umstand verleitete das IBE Projektteam zur Entwicklung eines neuen, zweistufigen Prozessmodells mit einer Makro- und einer Mikrostrategie, ähnlich den Lebensphasen und des Problemlösungszyklus im Systems Engineering (vgl. Abb. 3).
Auf der Makrostrategie-Stufe lassen sich Elemente des Problemlösungszyklus wiedererkennen. Die Zielfindung und Analyse ist zusammengefasst in einer Lebensphase. Anschliessend folgen die Schritte Lösungsfindung und Entscheidungsfindung.
Auf der Mikrostrategie-Stufe befindet sich das CRISP-DM Vorgehensmodell, welches im ersten Schritt als Mittel zur Diagnose dient. Eine erste Analyse der Daten und unerwartet auftauchende Probleme mit der Datenqualität können dazu führen, das zusätzliche Ziele hinsichtlich der Datenqualität in der Makrostrategie gesetzt werden. Data Science-Methoden, wie beispielsweise Process Mining, können hierbei in kurzer Zeit gute Analyseergebnisse liefern. In der Lösungsfindungsphase kommen dann prognostische Methoden zur Erstellung von Szenarien und Prognosen zum Einsatz. Hier wird der CRISP-DM Prozess erneut durchlaufen und die in der Zielfindungsphase entdeckten Probleme mit der Datenqualität können bereits behoben werden. In der Entscheidungsfindung und Umsetzung gilt es, die zu Beginn gesetzten und durch die Iterationen dazugekommenen Ziele mit den Lösungen zu vergleichen und eine optimale Entscheidung zu treffen. Eine wirtschaftliche und wissenschaftliche Herausforderung stellt hierbei der Einsatz von Künstlichen Neuronalen Netzen und selbstlernenden (intelligenten) Assistenzsystemen dar.
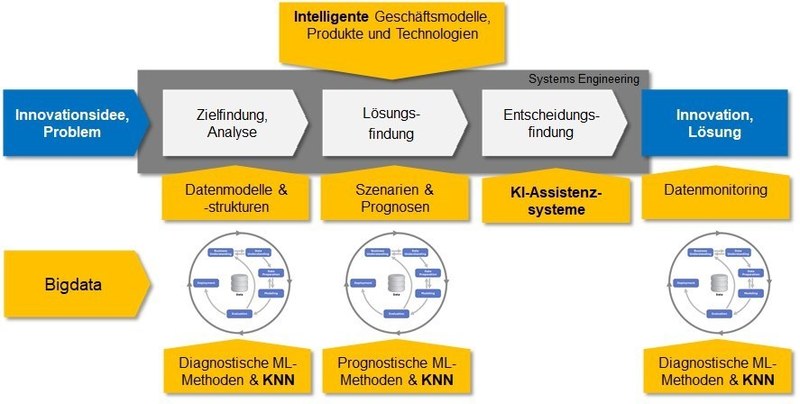
Abb. 3: Innovationsprozess mit Machine Learning (ML), Künstlichen Neuronalen Netzen (KNN) und KI-Assistenzsystemen (IBE, FHNW)
Mit der wachsenden Datenflut wird der richtige Umgang mit Daten immer mehr zu einem wichtigen Wettbewerbsfaktor und entscheidet damit über die Konkurrenzfähigkeit eines Unternehmens. Wie die Beispiele aus der Praxis zeigen, sind Data Science-Projekte deshalb nicht nur gut geeignet, um Muster in den Daten zu erkennen, sondern sie können auch langfristig dazu dienen, die Datenqualität zu verbessern. Dies setzt natürlich voraus, dass die erkannten Mängel in den Daten durch entsprechende Massnahmen behoben werden.
Massnahmen zur Erreichung einer hohen Datenqualität sind die Analyse der Daten (Data Profiling), die Zusammenführung mehrerer Datenquellen (Data Integration), die Bereinigung der Daten (Data Cleansing) und die Überwachung der von der Datenalterung beeinflussten Datenqualität (Data Monitoring). Mithilfe intelligenter, zum Teil selbstlernender Algorithmen wird es vermehrt möglich sein, die Datenanalyse-, Datenbereinigungs- und Datenüberwachungsvorgänge zu automatisieren und den manuellen Aufwand für die Sicherstellung einer hohen Datenqualität zu minimieren.
Kontakt
Alicem Azak
Institut für Business Engineering FHNW
Wissenschaftlicher Assistent
Telefon: +41 56 202 80 51
E-Mail: alicem.azak@fhnw.ch
Prof. Dr. Raoul Waldburger
Leiter Institut für Business Engineering FHNW
Telefon: +41 56 202 71 83
E-Mail: raoul.waldburger@fhnw.ch