Studierende berichten: Geomatik-Frühlings-Kolloquium vom 14.04.2026
Geoharvester.ch – ein Suchmaschinenprototyp für Schweizer Geodienste
Die Suche nach passenden Geodiensten verteilt sich oft auf mehrere Geoportale mit unterschiedlichen Strukturen. Endpunkte sind nicht immer eindeutig, Metadaten uneinheitlich oder unvollständig. Ein zentraler Zugangspunkt fehlt. Genau dieses Problem adressiert das Projekt «Geoharvester.ch», das am Frühlings-Kolloquium 2026 von Prof. Dr. Pia Bereuter, Friedrich Striewski und Elia Ferrari vom Institut Geomatik der FHNW vorgestellt wurde und den Zugriff auf Geodienste deutlich vereinfacht.
Seit 2022 entwickelt das Institut Geomatik der FHNW gemeinsam mit dem Bundesamt für Landestopografie swisstopo einen Prototypen, der Geodienste systematisch auffindbar macht: Geoharvester.ch. Ziel ist eine Suchmaschine, die verteilte Dienste automatisch erfasst, aufbereitet und zentral zugänglich macht.

Die technische Grundlage bildet ein automatisierter Prozess, bei dem rund 1400 Quellen regelmässig abgefragt werden. Die Metadaten werden über GetCapabilities-Anfragen extrahiert, anschliessend bereinigt und in eine zentrale Datenbank überführt. Der Ablauf ist klar aufgebaut: sammeln, aufbereiten und speichern. Dieser Vorgang wird wöchentlich wiederholt und führt mittlerweile zu einem grossen Datenbestand von rund 76’000 unterschiedlichen Datensätzen.
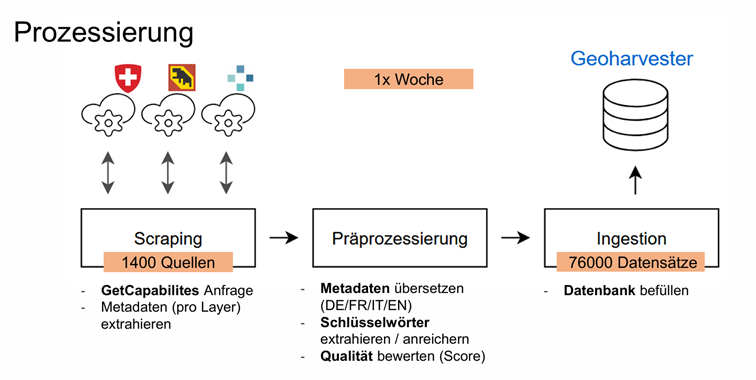
Im Vortrag wurde schnell klar, wo das eigentliche Problem liegt: nicht beim Zugriff auf die Daten, sondern bei deren Beschreibung. Viele Geodienste sind vorhanden, aber aufgrund mangelhafter Metadaten kaum auffindbar. Titel bleiben oft zu allgemein, Abstracts fehlen oder wiederholen lediglich den Titel, und aussagekräftige Schlüsselwörter sind häufig nicht vorhanden. Teilweise sind selbst Kontaktangaben unbrauchbar. Die Lösung des Geoharvesters: die Schlüsselwörter werden aus den vorhandenen Metadaten extrahiert und angereichert. Die Qualität wird systematisch bewertet und jeder Datensatz erhält einen Wert zwischen 0 und 100, der direkt in die Suchergebnisse einfliesst. Dieser Ansatz macht die Unterschiede in der Metadatenqualität unmittelbar sichtbar.
Am Anfang lief die Verarbeitung zwar technisch stabil, im Alltag zeigte sich aber schnell ein praktisches Problem: die Laufzeit. Die erste Pipeline arbeitete zuverlässig, brauchte jedoch so lange, dass sie an die Systemgrenzen stiess. Der Fokus lag deshalb früh auf Optimierung. Statt bei jedem Durchlauf alle Daten neu zu verarbeiten, werden inzwischen nur noch tatsächlich geänderte Inhalte berücksichtigt. Grundlage dafür ist ein Hash-Verfahren, das Änderungen gezielt erkennt. Der Effekt ist deutlich: Die Laufzeit konnte von rund 16 Stunden auf etwa 2 Stunden reduziert werden.
Noch deutlicher zeigt sich der Unterschied bei der eigentlichen Suche. Eine reine Stichwortsuche reicht hier schlicht nicht aus. Gerade bei mehrsprachigen und uneinheitlichen Daten stösst sie schnell an Grenzen. Deshalb kommen Methoden der natürlichen Sprachverarbeitung dazu. Suchbegriffe werden bereinigt, Stoppwörter entfernt und Begriffe auf ihren Wortstamm reduziert. Anschliessend werden sie inhaltlich interpretiert und mit einem Knowledge Graph abgeglichen, der Synonyme und Übersetzungen verknüpft. Erst danach erfolgt die eigentliche Abfrage in der Datenbank.
Gerade in der Schweiz wird dieser Ansatz entscheidend. Der Geoharvester verarbeitet Daten in Deutsch, Französisch, Italienisch und Englisch und übersetzt zentrale Inhalte wie Titel und Schlüsselwörter automatisch. Dadurch werden auch Datensätze auffindbar, die ursprünglich in einer anderen Sprache beschrieben sind. Zusätzlich werden Schlüsselwörter aus den Beschreibungen extrahiert und erweitert. Das Sprachmodell verknüpft diese Begriffe und stellt Zusammenhänge her, die über eine reine Stichwortsuche hinausgehen.
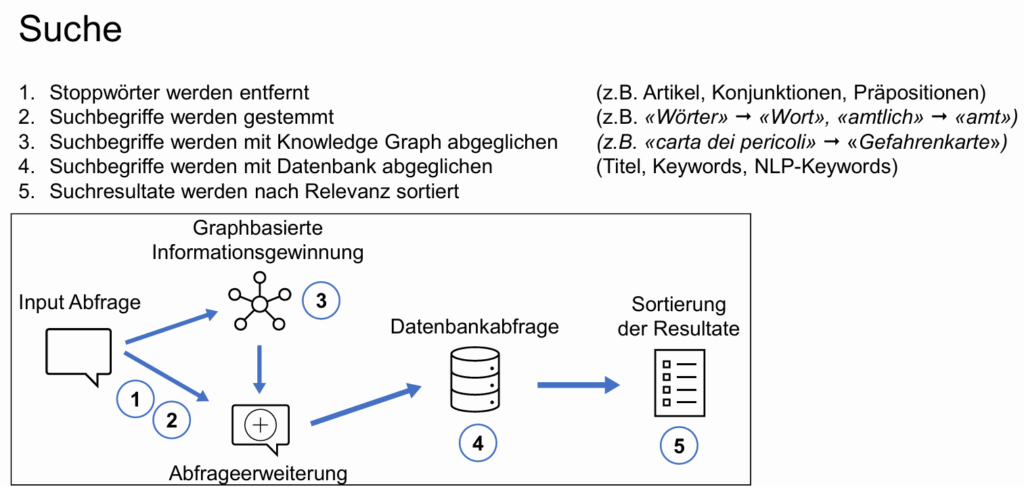
Die Ergebnisse der Suche werden nicht ungeordnet angezeigt, sondern nach Relevanz sortiert. Berücksichtigt wird, ob ein Suchbegriff exakt oder nur ungefähr mit vorhandenen Inhalten übereinstimmt. In welchen Feldern kommt er vor und wie gut sind die zugrunde liegenden Metadaten beschrieben? So entsteht eine priorisierte Ergebnisliste, die deutlich zielgerichteter ist als eine einfache Stichwortsuche.
Neben der technischen Verarbeitung ist auch die Anwendung klar strukturiert. Keine überladene Oberfläche, sondern klare Filter, tabellarische Darstellung mit Sortierfunktion sowie direkte Interaktion mit Schlüsselwörtern für weitere Zusammenhänge. Gleichzeitig gibt es eine API, über die sich die Suche in eigene Anwendungen integrieren lässt.
Für uns wurde im Vortrag spürbar, dass sich die Herausforderung mit dem Umgang mit Geodiensten verschiebt. Es stellt sich nicht mehr die Frage, ob Daten vorhanden sind, sondern wie gut sie beschrieben und auffindbar sind. Der Geoharvester zeigt eindrücklich, wie stark diese Aspekte zusammenhängen und wie sie technisch adressiert werden können. Auch im Kontext von KI bleibt die Suche zentral, da auch KI-Modelle nur mit den Daten arbeiten können, die sie finden.
Der Geoharvester ist aktuell zwar ein Prototyp, demonstriert jedoch, in welche Richtung sich solche Systeme weiterentwickeln können. Mehr Schnittstellen, stärkere Verbindung der Datenbank mit Sprachmodellen, vielleicht auch visuelle Zugänge über Karten. Vieles davon wirkt nicht weit entfernt. Für die Weiterentwicklung und den langfristigen Betrieb von Geoharvester werden zusätzliche Partner und Sponsoren gesucht. Das Projekt soll weitergeführt und ausgebaut werden, um den praktischen Nutzen für die Geodaten-Branche weiter zu erhöhen.
Geodaten entfalten ihren Wert erst, wenn sie gefunden werden – Geoharvester reduziert den Suchaufwand, macht relevante Dienste schneller sichtbar und schafft eine verlässliche Grundlage für Projekte im Studium und in der Praxis.
Eine Aufzeichnung des Vortrages finden Sie hier.
Autoren: Jan Hänisch und Sarah Schrenk, Studierende Bachelor in Geomatik im 4. Semester
Kommentare
Keine Kommentare erfasst zu Studierende berichten: Geomatik-Frühlings-Kolloquium vom 14.04.2026